
Drop-In Class #3: NLP, and how a machine "reads" words
The thing you should know before you try to learn about LLMs

Welcome to my newsletter, which I call Drop-In Class because each edition is like a short, fun Peloton class for technology concepts. Except unlike a fitness instructor, I'm not an expert yet: I'm learning everything at the same time you are. Thanks for following along with me as I "learn in public"!

NLP: the thing that you should know before you learn about LLMs
In my last Drop-In, I covered unstructured data. Now we’re going to check out one of the ways a machine processes unstructured data.
Originally I was going to dive right into LLMs. But trying to understand LLMs is like trying to learn a Simone Biles triple-double before you do a cartwheel.
To understand why LLMs are so cool, there’s a fundamental concept that we need to cover first: Natural language processing (NLP). That’s the cartwheel before the triple-double.
NLP is the ability of a machine to comprehend and generate human language. But how does a machine “know” the meanings of each sentence we feed it? That’s what you’re going to find out in today’s class.
Before we keep going: it wouldn’t be a drop-in class without a good playlist! Here is today’s on-theme music selection. Throw it on and let’s dive in.
What are words for? How a machine “understands” text
How does the model know what I’m saying?
This is the question at the heart of the generative AI use cases we’re talking about today, like text summarization, translation, speech recognition and information retrieval.
Let’s say I have a record store where I sling 80’s albums and I want to analyze the Google reviews of my store. This is a job for NLP! Sentiment analysis is a good example of a machine “interpreting” text.
Step 1: Turn the words into numbers
There’s a language barrier between us and machines. As I covered in my last edition about unstructured data, machines don’t speak words. They speak numbers. And natural language processing means we’re making the computer deal with words.
So for our model to “read” the Google reviews, first it needs the words to be represented as numbers.
So we do a few things that turn the text into something the machine can interpret:
Tokenization: We turn each chunk of text in the Google review into numbers. At this step you might also do additional pre-processing, like assigning each word’s part of speech, or removing stop words (unimportant filler words like “the”).
Feature extraction: Here we represent each piece of text as a numerical feature.
Embedding is a popular feature extraction technique these days: you map out each word as a vector in space — think of it as a coordinate on a map that tells the algorithm where each word is in relation to other words. Closely related words appear closer together.
I’ll do a separate explainer just on vector embedding (it’s fascinating) but for now, here’s a basic diagram of where we’re at so far:
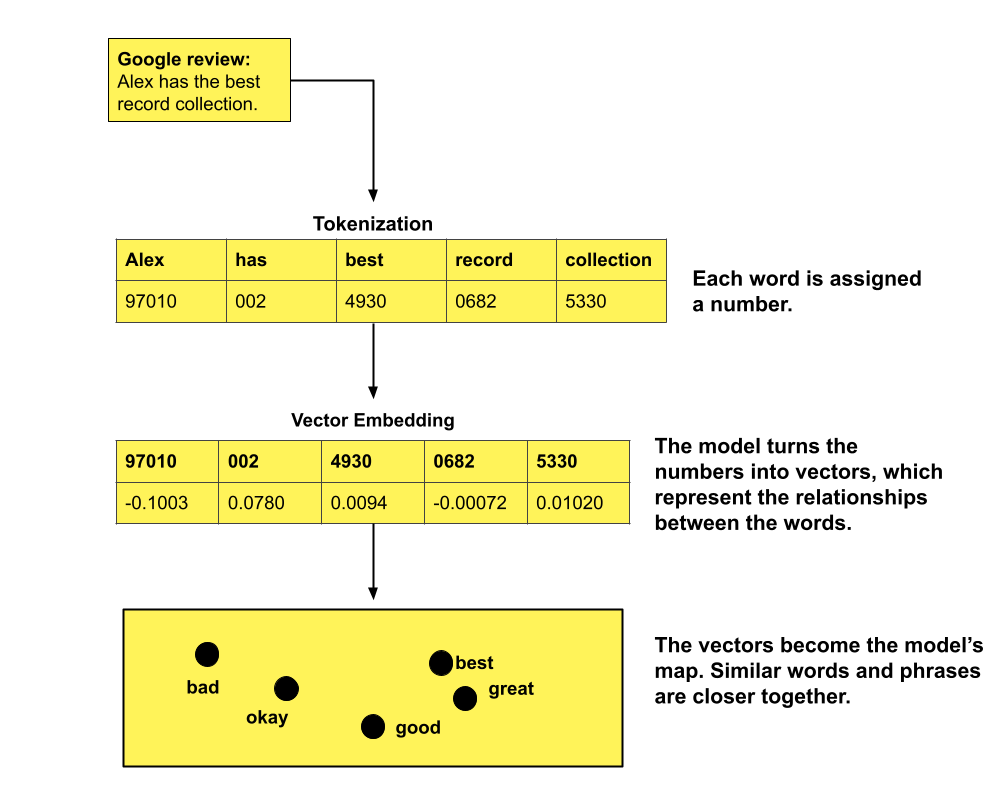
Step 2: Put the numbers into an algorithm that makes a very educated guess
So we’ve taken the Google review text, turned it into numbers, then mapped out how those numbers are related by representing them as points in a space.
Now it’s time for the model to work with those numbers. And how do computers work with numbers? Math!
The computer doesn’t get to the answer the way a human would. It has to use an algorithm to make predictions about what it thinks the answer is. That’s all it is: a guess. A very, very, educated guess, but still a guess.
The model takes the numerical features as input. Then it uses an algorithm to calculate the probability that the review is positive, based on patterns it learns during training. It knows that a review with the word “best” likely equates to “positive,” because I trained it on a dataset of Google reviews that I labeled as positive or negative.
You can choose different models and algorithms depending on the task. For this example, we’ll say we’re using an algorithm called Support Vector Machines (SVM), which can group the vectors into categories like “Positive” and “Negative.”
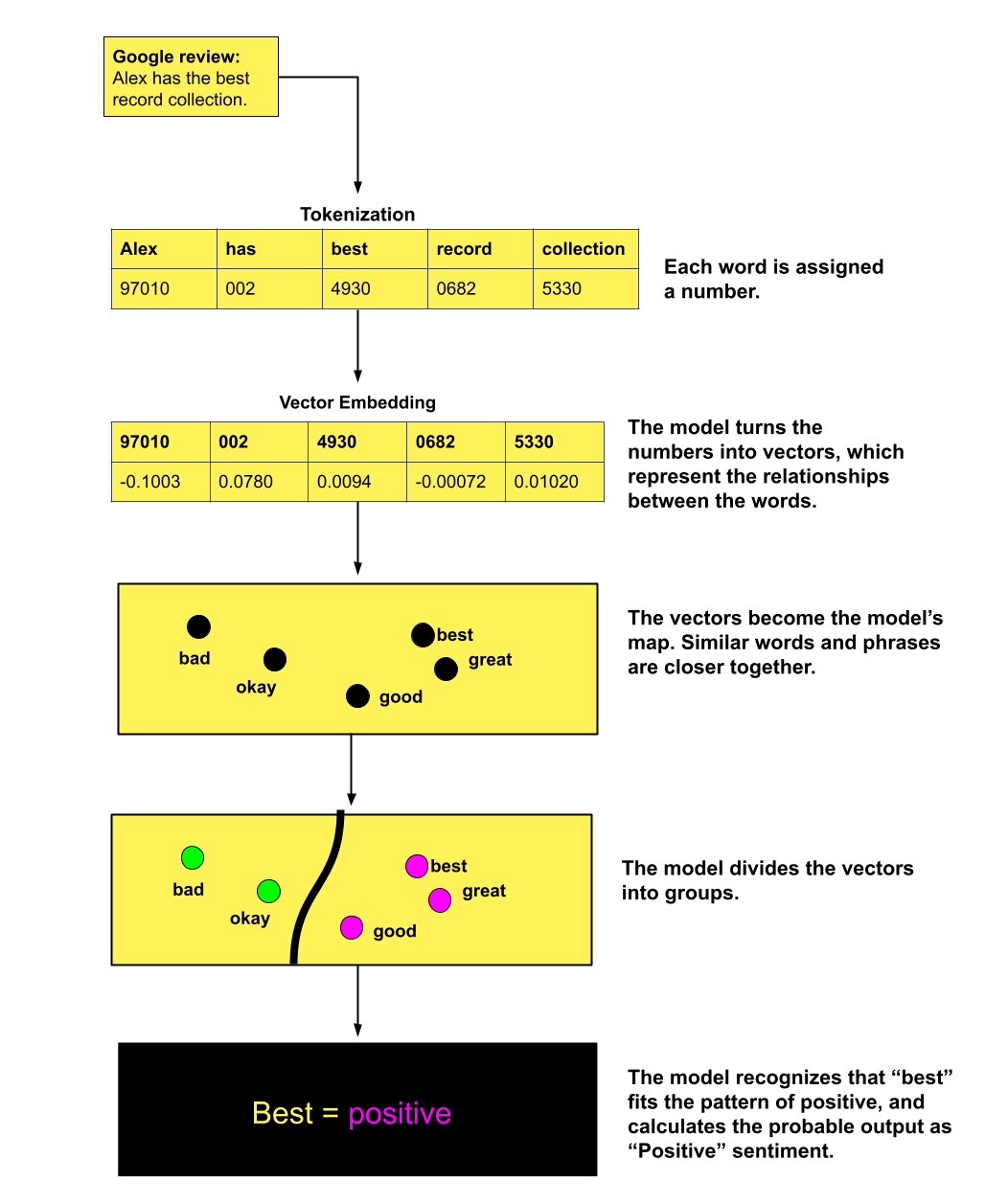
And that’s how the machine does it. It’s not reading anything. It doesn’t understand meaning. It doesn’t know what words are for. It’s doing cold, hard algebra.
So now you can do a cartwheel. And since you know a little more about how natural language processing works, it’ll be easier to get why LLMs are such a big deal. They’re doing NLP on steroids, with more sophisticated methods and massive amounts of data.
The things a model has to go through, just to sound like us! Too bad it can’t actually appreciate 80’s music.
Extra credit reading:
As always, I dramatically oversimplify my topics because this is a 101-level drop-in class. Here are helpful sources to dig deeper:
Text Classification: What it is And Why it Matters (MonkeyLearn)
An intuitive introduction to text embeddings (StackOverflow)
See you in the next drop-in! I’ll be breaking down LLMs. Get ready.
-Alex G
P.S. Some fun word trivia for you: The Missing Persons album Spring Session M. is an anagram of Missing Persons.
I tried to get ChatGPT to tell me a fun fact about Missing Persons, and it did its best.
