
Drop-In Class #5: LLMs, part 2: How a machine pays attention
Why the attention mechanism makes LLMs different from previous models
Welcome to my newsletter, which I call Drop-In Class because each edition is like a short, fun Peloton class for technology concepts. Except unlike a fitness instructor, I'm not an expert yet: I'm learning everything at the same time you are. Thanks for following along with me as I "learn in public"!

In my last Drop-In Class, I started getting into how LLMs work, with the first step of the process: vector embedding.
Now it's time to get at the heart of what makes today’s LLMs different from previous models. The attention mechanism, and what the steps look like in what’s called a transformer.
Does it sound like a lot? It is a lot. We’re talking about groundbreaking stuff here! But not to worry: I keep the focus on the most important concepts.
Time to put on today’s music selection! We’re going with “Don’t Let Me Be Misunderstood” because this is about how LLMs work really hard to pay attention and understand what you really mean.
Self-attention: Reading the entire directions so you can tell what’s important
Did you ever have someone warn you to "read the full directions before you start"? Like in school when you're taking a test, or when you’re reading through a recipe in a cookbook. You need the whole context before you get started. You need to make sure you’re not using up all of your butter too early in the recipe.
Without the attention mechanism, traditional neural networks just charge ahead instead of reading the directions as a whole. They process your text sequentially.
That means they read your input one...word...at...a...time.
This works just fine in many cases. But it becomes a problem when you ask a model to parse through longer things, like an entire passage of text.
Imagine typing this prompt into a chatbot: “How can I use the squash I got at the farmer’s market? I need recipe ideas.”
The model will need to understand that squash means the vegetable, not the sport, or the verb meaning to crush something. And it won’t get that by only looking at squash. It needs the context of the other words around it, like farmer’s market and recipe ideas, cluing you in that we’re talking about a vegetable.
In other words, it needs to pay attention.
So eight Google researchers came together in 2017 and wrote a breakthrough paper called “Attention Is All You Need.”
(If you’re wondering, the title was indeed inspired by the Beatles and “All You Need Is Love.” I live for this kind of trivia.)
This paper is THE paper in the AI world. The more you read about AI, the more you’ll run into this paper. Because it’s a big deal. “Attention Is All You Need” put forward a new approach that solves the context problem: self-attention.
Attention is what allows a neural network to focus specifically on the most relevant parts of an input sequence, by taking the full context into account. A neural network with self-attention can better understand a word’s intent by considering all of the information in the input in parallel, not just one chunk at a time.
Here's how it works:
Instead of receiving only some of the data at a time, the model processes your input all at once, in parallel — so the model can read all the directions at the same time, and it can do it fast.
“Weights” are assigned to parts of the sequence, with the most important parts getting the highest weights.
The model calculates an “attention score” for each word, by scoring the word against the rest of the input sentence. This is done using a lot of matrix calculations that I won’t go into here.
So instead of processing a sequence from start to finish, the model can look at the phrases that are most important for getting the overall meaning.
But where is all of this attention happening? In a transformer architecture.
Transformers: the type of model that pays attention
A transformer model is a type of deep learning model that relies solely on the attention mechanism. Because remember: attention is all you need!
Yep, the transformer was introduced in “Attention Is All You Need.” I told you that paper would keep popping up.
There are two basic things going on in a transformer model: encoding, and decoding. It’s straightforward at a high level: one thing goes in, another thing comes out.
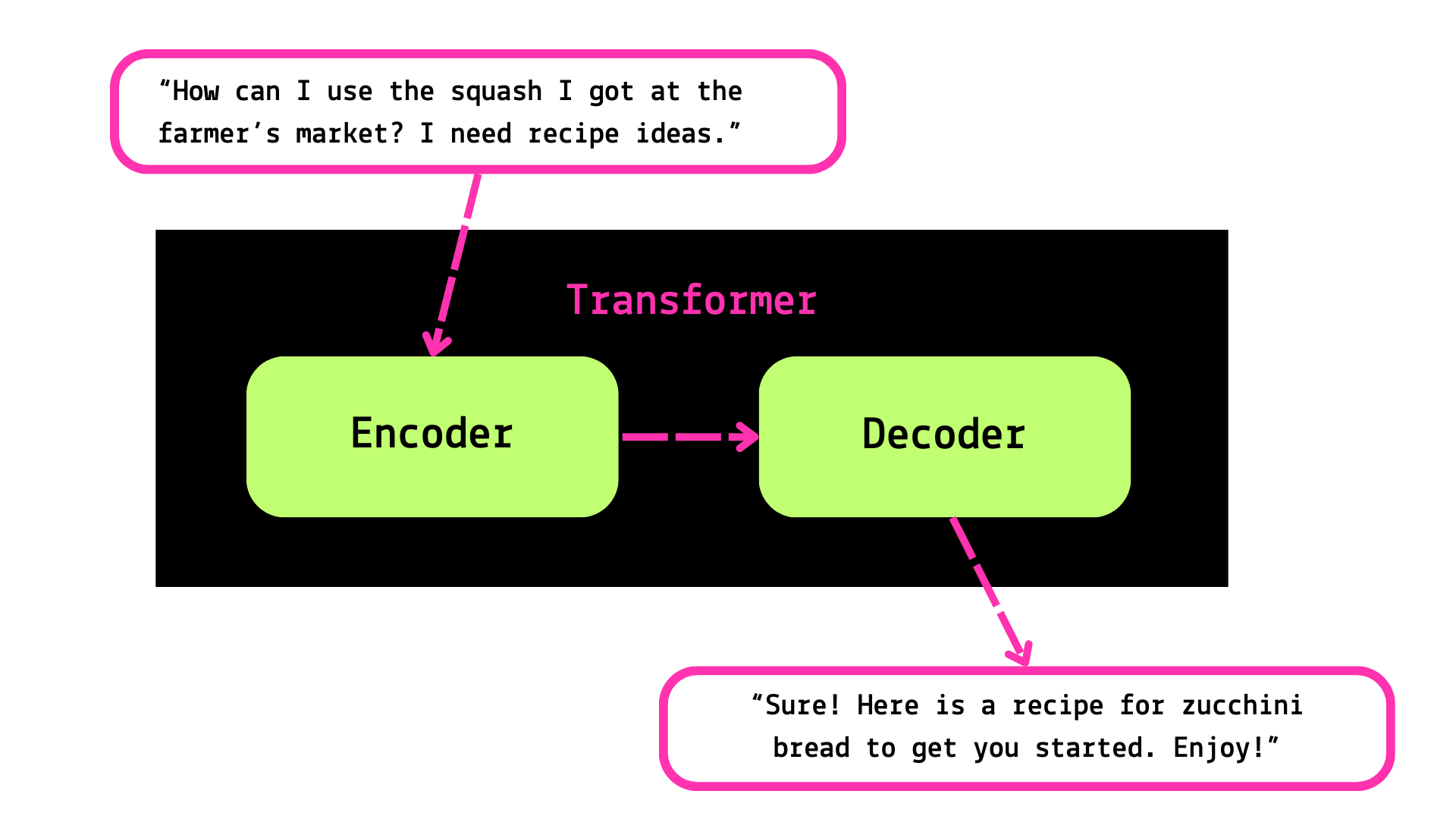
But of course, there’s a lot more going on in that mysterious black box.
So for our grand finale, let’s put it all together. You can read back through my previous editions for the first steps!
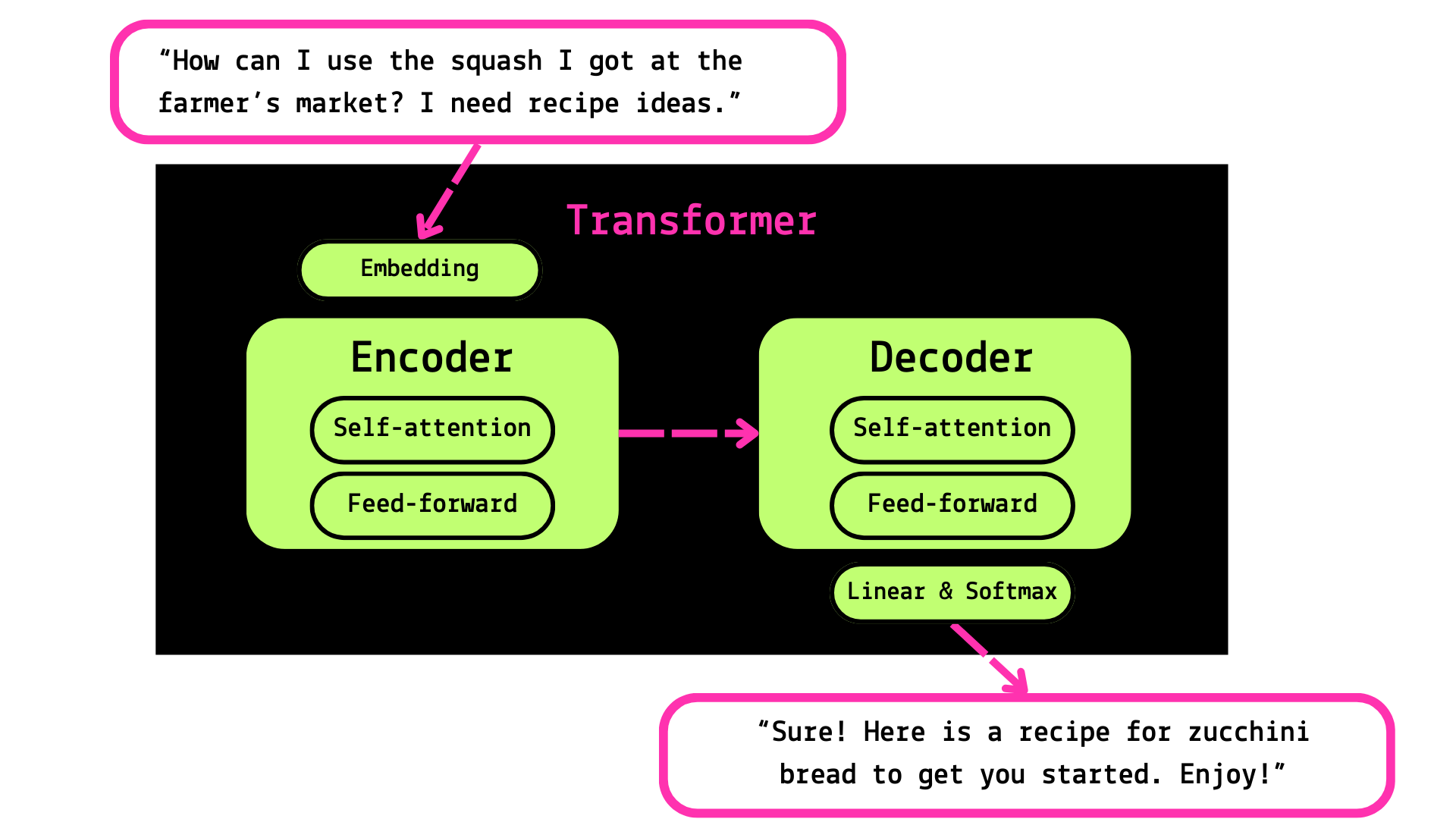
Pre-processing and tokenization: each chunk of text is turned into numbers.
Embedding: The numbers are turned into vectors, which represent the semantic similarities of the words as points in space.
Self-attention: The encoder looks at the relevant parts of the sentence and does a bunch of calculations to determine the attention score for each word.
Feed-forward: The encoder passes the attention score to a “feed-forward” neural network, which basically predicts the next word and passes it along.
The decoder: The decoder takes the input sequence and follows a similar process of attention and feed-forward, with the added step of creating the output in the final layers (called “linear” and “softmax”).
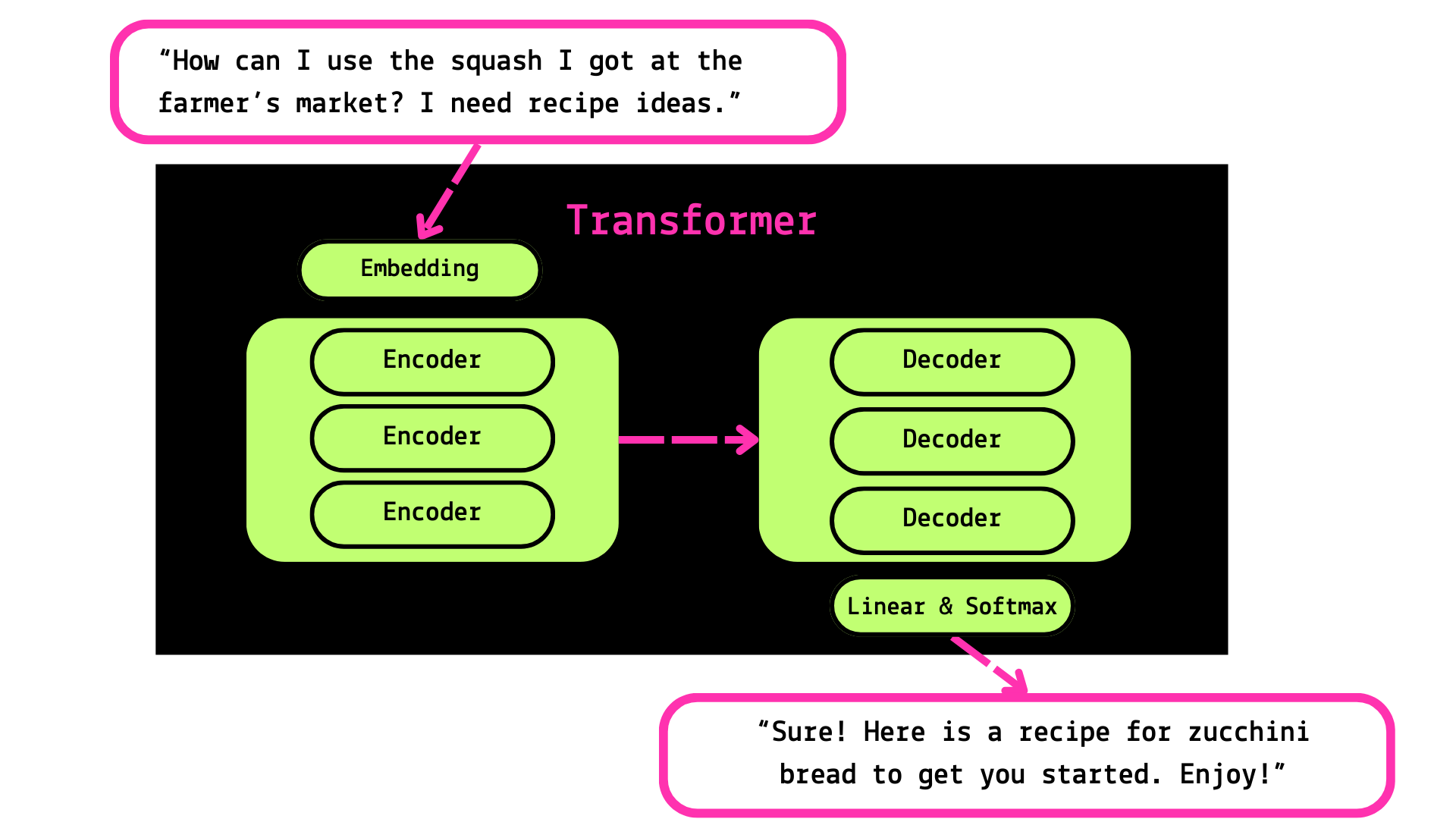
One more thing to make your brain hurt: this is repeated over and over, in as many layers of encoders and decoders as it takes.
You’ve made it through the basics of LLMs! What was the point?
“What did I just read?” you’re asking me now. Breaking down the inner workings of an LLM is a lot. Why bother going through it all, if you’re not actually trying to build these things from scratch?
Because it’s good to know on a fundamental level what’s going on in the transformer black box. You can pay a little more attention to what’s going on behind the curtain.

Many everyday applications you’re using, from Google search, to recommendation systems, to voice assistants, to ChatGPT, are using a transformer model. A little awareness goes a long way when it comes to understanding what’s going on behind the scenes. It’s not wizardry. It’s machinery. Very impressive machinery, but machinery.
By the way, did you know GPT stands for Generative Pre-trained Transformer? That should make a lot more sense now that you’ve read all this.
Extra credit reading:
As always, I dramatically oversimplify my topics because this is a 101-level drop-in class. For more reading, dive into these great articles:
The Illustrated Transformer (GitHub)
Transformer Models (Cohere)
Transformer Models and BERT (Google Cloud Skills Boost)
See you in the next drop-in! We’ll be shifting gears and taking a break from AI.
-Alex G